
The Vision
Every person generates a massive digital footprint scattered across email providers, cloud drives, bank portals, photo libraries, and local files. Accessing your own data requires logging into dozens of services, each with their own interface, each holding a fragment of your life.
Agentic Node is a personal data platform that pulls all of this into one place, indexed and searchable through a conversational AI agent. The core principle:
Unlike cloud-first AI assistants that upload your data to external servers, Agentic Node runs locally. Your documents are chunked and embedded on your machine. Your LLM runs on your hardware. Your financial data never touches an external API unless you explicitly allow it. The result is an AI that knows everything about your life while maintaining complete privacy.
System Architecture
The platform uses a hybrid storage architecture with specialized data stores, a dual LLM pipeline, and a connector framework that pulls data from any source into the user's local Node.
=========================================================================================== DEVICES (Access Points) =========================================================================================== Desktop Laptop Mobile Remote Workstation | | | | +------------------+-------------------+----------------------+ | [ Browser / PWA ] localhost:3000 or LAN | =========================================================================================== FRONTEND (React + TypeScript + Tailwind + Vite) =========================================================================================== | +----------------+----------------+ | | [ Agent Chat UI ] [ Connections Dashboard ] Named personal agent Data source management Source citations Folder browser Privacy indicators RAG progress bars LLM tier selector Sync controls | | +----------------+----------------+ | [ FastAPI Backend ] Port 8000 (Docker) | =========================================================================================== AGENT LAYER (The Conductor) =========================================================================================== | +----------+-----------+-----------+----------+ | | | | | Query Router Privacy RAG Service Structured Connector (local/cloud) Service (retrieval) Query Svc Framework | | | | | | [ spaCy NER ] | | | | PII detection | | | | Tokenization | | | | | | | | =========================================================================================== DATA STORES (Hybrid Architecture) =========================================================================================== | | | | | | | [ FAISS Index ] [ SQLite DB ] [ File System ] | | 384-dim vectors Transactions Raw media | | Semantic search Contacts Photos/Video | | Document chunks Calendar Audio files | | Email content File metadata PDFs/Docs | | | | | =========================================================================================== RAG PIPELINE (Retrieval Augmented Generation) =========================================================================================== | | | | | User Query | | | | | Embed query (all-MiniLM-L6-v2, 384-dim) | | | | | FAISS similarity search (cosine, top-k) | | | | | Retrieve top chunks + similarity scores | | | | | Build context prompt with sources | | | | | v =========================================================================================== LLM PIPELINE (Dual-Mode Processing) =========================================================================================== | +--------+--------+ | | [ LOCAL LLM ] [ CLOUD LLM ] Mistral 7B Claude API via Ollama (Anthropic) Port 11434 | (Docker) Receives ONLY: | - Anonymized context 100% private - PII tokens replaced No data leaves - User controls access | | +--------+---------+ | [ Response ] De-anonymize tokens Attach source citations Privacy report | v [ User sees answer ] with sources + privacy indicator =========================================================================================== DATA CONNECTORS (Everything Comes TO You) =========================================================================================== [Local Folders] [Cloud Storage] [Email/Cal] [Banking] [Contacts] [Photos] C:, D:, USB OneDrive IMAP Plaid API Phone Libraries External SSD Google Drive CalDAV Investment Social Albums NAS drives Dropbox OAuth Accounts LinkedIn EXIF data iCloud | | | | | | +---------------+---------------+-----------+----------+-----------+ | Pull data DOWN to local Route to correct store: - Text docs --> FAISS (chunk + embed) - Structured --> SQLite (tables) - Media --> File system (metadata indexed)
- FAISS Vector Store - Unstructured text (documents, emails, notes). Queried via semantic similarity for natural language questions like "what's my mom's birthday?"
- SQLite Database - Structured data (financial transactions, contacts, calendar events). Queried via SQL for aggregation, graphing, and filtering. Chosen over Postgres because it is free, zero-config, and a single portable file.
- Local File System - Raw media files (photos, videos, audio). Metadata indexed in SQLite, text content indexed in FAISS.
- Local LLM (Mistral via Ollama) - Acts as a privacy gatekeeper. Handles queries locally and strips PII before anything reaches a cloud LLM.
- Cloud LLM (Claude API) - Optional tier for complex reasoning. Receives only anonymized, tokenized context. User controls when this is used.
- RAG Pipeline - Documents are chunked, embedded with all-MiniLM-L6-v2 (384 dimensions), and stored in a FAISS index. At query time, the user's question is embedded and matched against stored chunks using cosine similarity. Top-k results are assembled into a context prompt for the LLM.
- spaCy NER - Named entity recognition identifies PII (names, addresses, phone numbers) in outbound context. Sensitive tokens are replaced before cloud processing and restored in the response.
Access From Any Device
Agentic Node runs as a local service accessible from any device on the user's network. The Node itself lives on one machine (or a dedicated appliance), but the web-based interface works from any browser.
Privacy-First Data Hierarchy
Not all data sources are equal. The platform implements a three-tier privacy hierarchy that determines how data is ingested and stored:
Application Screenshots
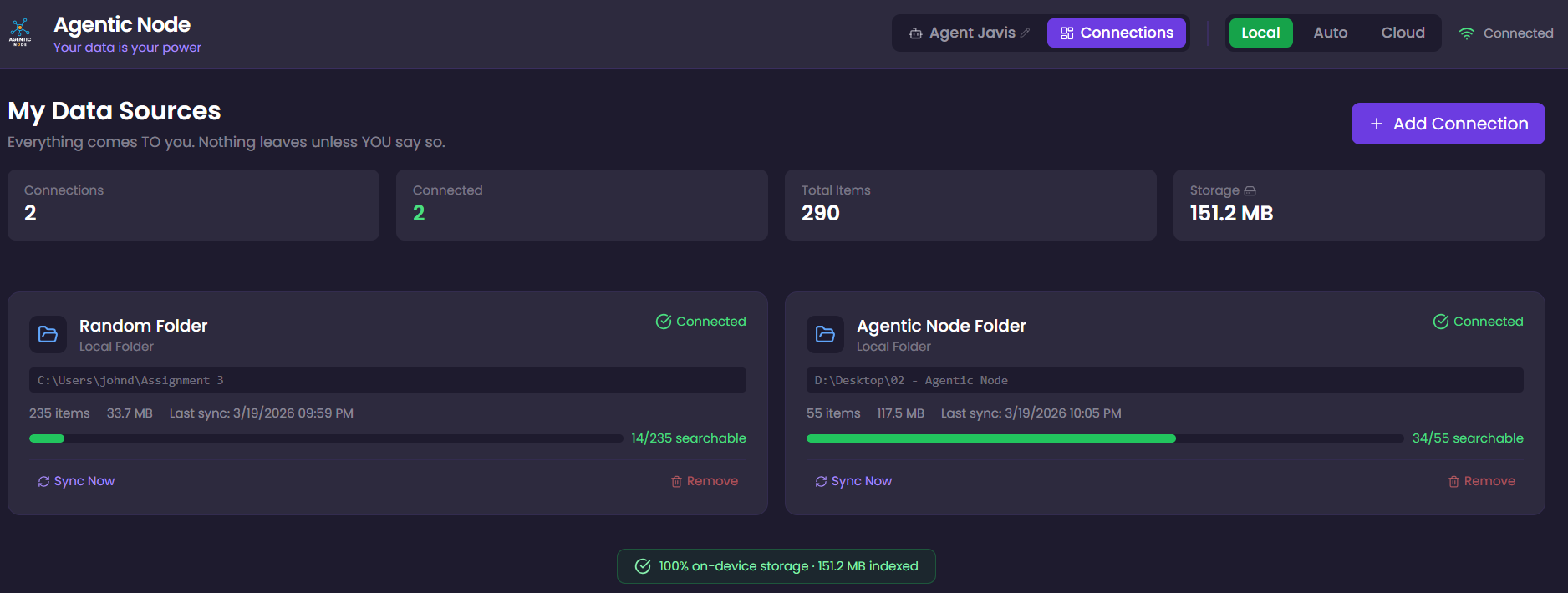
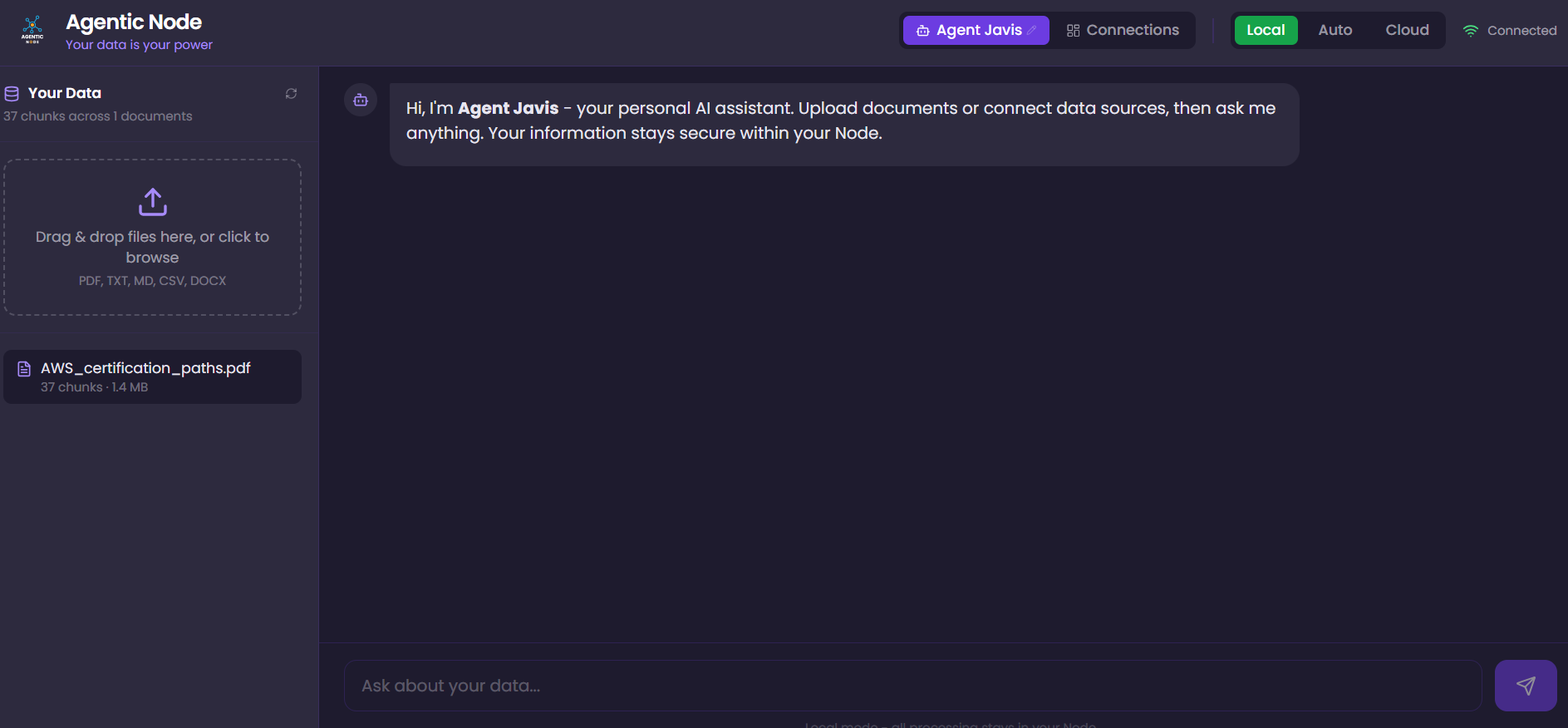
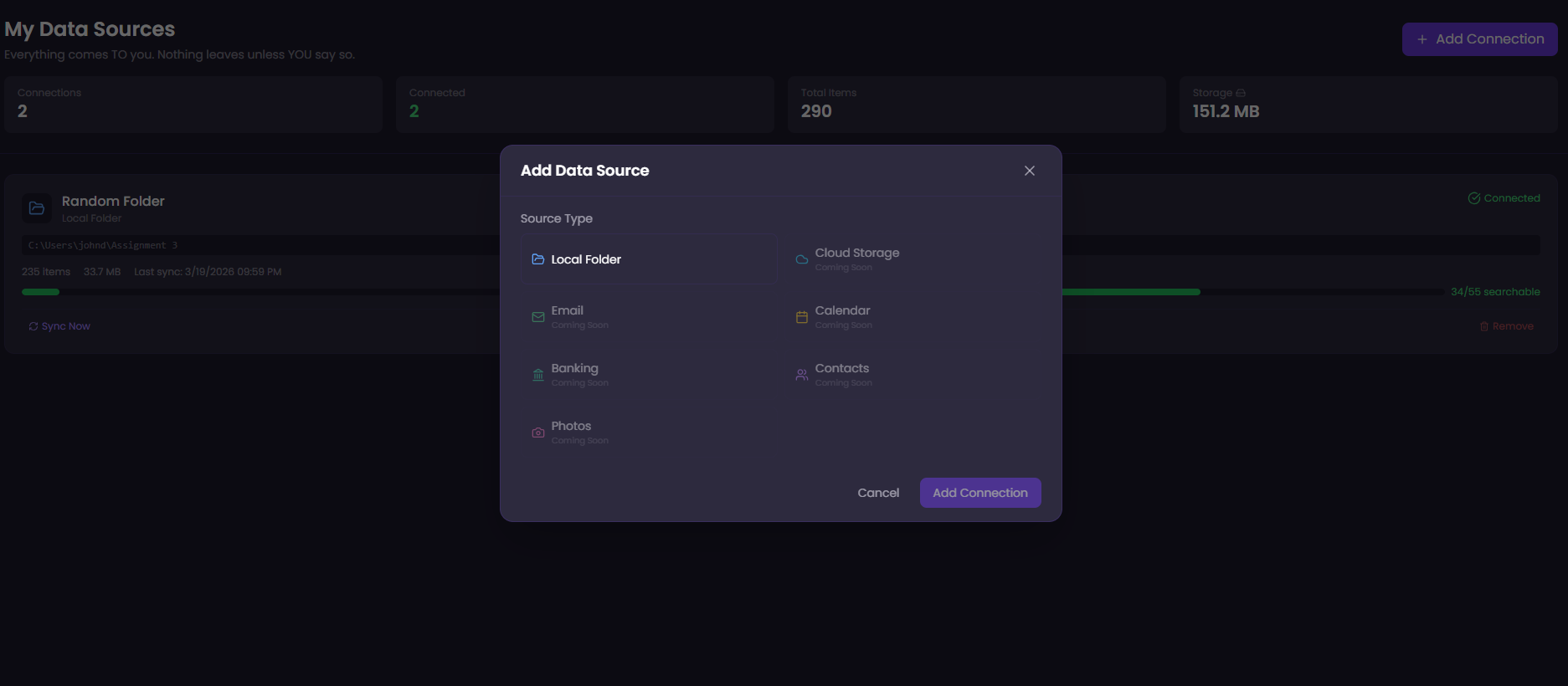
Connections Dashboard
The platform includes a visual dashboard for managing all data source connections. Users can browse their local file system, connect folders, and monitor sync status, including a real-time progress bar showing how many files have been chunked and embedded into the RAG pipeline.
Supported connector types:
- Local Folders - Browse and select any folder on any mounted drive. Files are cataloged in SQLite and text documents are automatically chunked and embedded into FAISS for search.
- Cloud Storage - OneDrive, Google Drive, Dropbox, iCloud. Pulls files down to local storage.
- Email - IMAP/OAuth integration. Pulls emails down for local indexing.
- Calendar - CalDAV/OAuth. Syncs events to structured database.
- Banking - Plaid API. Fetches transaction history for financial queries and visualization.
- Contacts & Photos - Additional connector types for comprehensive data aggregation.
Each connection card shows: connection status, item count, storage size, last sync time, and a RAG indexing progress bar indicating how many files are searchable through the AI agent.
The Personal Agent
The front-end experience is a conversational AI agent that users can name and interact with naturally. The agent understands context from all connected data sources and provides sourced answers with citation links back to the original documents.
Key capabilities:
- Natural language queries across all personal data: "When is my mom's birthday?" or "What did I spend on groceries last month?"
- Source citations with similarity match percentages
- Privacy indicator showing whether data stayed local or was sent to the cloud
- Three LLM modes: Local (100% private, Mistral), Cloud (faster, Claude API with anonymization), Auto (intelligent routing)
- User-configurable agent name persisted across sessions
Engineering Challenges & Solutions
Building a platform that orchestrates Docker containers, local LLMs, vector databases, and streaming APIs surfaced several non-trivial engineering challenges. Here are the most instructive ones:
Hypothesis 2: Frontend state mutation. The streaming callback was mutating state directly instead of creating new objects. Fixed immutability pattern. Did not fix it.
Hypothesis 3: Backend SSE streaming. The httpx library's
aiter_lines() was yielding duplicate lines from Ollama's NDJSON response stream.
stream: false). The complete response returns at once, eliminating any doubling. Confirmed the issue was isolated to the streaming pipeline layer.
docker exec agentic-node-ollama-1 ollama pull mistral
netstat -ano | findstr :8000 to identify the process, found a leftover container from a previous project still running. Stopped it with docker stop and removed it.
docker ps reveals all running containers. Auto-restart policies on old containers can cause persistent conflicts.
Technology Stack
Roadmap
- Cloud storage connectors (OneDrive, Google Drive, Dropbox, iCloud)
- Email and calendar integration via IMAP/CalDAV
- Banking integration via Plaid API for financial queries and visualization
- Progressive token streaming for real-time response display
- Encrypted-at-rest with user-held keys for optional cloud backup
- Hardware vision: always-on router appliance with SSD storage
- Developer marketplace for third-party connectors